Filter-Sätze
Speicher eine Suche einmal — funktioniert im Editor, im Lese-Modus und im Export.
Inhalt
Wenn du nur einen Ausschnitt brauchst
Du arbeitest an Akt 2 deines Romans. Du willst die Anna-POV-Szenen am Stück lesen — nicht die ganzen 78 Szenen, nur Annas. Du musst den Bogen ihrer Stimme prüfen, ohne von Bobs Kapiteln abgelenkt zu sein.
In Word ist das nicht möglich. Die Datei ist eine lange Reihe von Wörtern. Du kannst nach "Anna" suchen, aber das findet jeden Treffer, nicht ihre Szenen.
In Scrivener kannst du eine Collection anlegen — du markierst manuell die Anna-Szenen, fertig. Aber wenn du nächste Woche eine neue Szene schreibst, in der Anna POV ist, ist sie nicht automatisch in der Collection. Du musst sie händisch hinzufügen. Und wenn du dieselbe Sicht auch im Compile haben willst — noch eine separate Konfiguration.
Im Novumdraft-System sind solche Sichten Filter-Sätze. Du baust eine Suche einmal — "POV: Anna" — und gibst ihr einen Namen. Sie funktioniert sofort an drei Stellen: im Editor (du siehst nur die gefilterten Szenen), im Lese-Modus (du liest die gefilterten Szenen typografisch gesetzt) und im Export (du schickst nur die gefilterten Szenen als PDF/DOCX/EPUB).
Sechs Filter-Dimensionen
Ein Filter-Satz kann auf sechs Achsen filtern. Jede ist optional; du kombinierst sie nach Bedarf:
POV-Figur
Wessen Perspektive? Eine Liste von Figuren — die Szene zählt, wenn ihre POV-Figur in der Liste ist. Logik: ODER (eine von vielen).
Beispiel: "Anna oder Bob" → alle Szenen, die aus einer der beiden Perspektiven geschrieben sind.
Cast (Figuren auf der Bühne)
Welche Figuren tauchen in der Szene auf? Hier gibt es zwei Modi:
- Alle ausgewählten (UND): die Szene muss jede der ausgewählten Figuren enthalten.
- Eine der ausgewählten (ODER): die Szene reicht, wenn eine der Figuren da ist.
Beispiel: Cast "alle" = Anna + Bob → nur Szenen, in denen Anna und Bob auf der Bühne stehen. Cast "eine" = Anna + Bob → alle Szenen mit Anna oder Bob.
Mit dieser Doppelung baust du komplexere Suchen: "Szenen mit Anna UND Bob, ODER Szenen mit Marcus UND Lara" — als zwei kombinierte Cast-Bedingungen.
Schauplätze
Welche Orte? Eine oder mehrere. Logik wahlweise UND oder ODER (über den Set-weiten Mode-Schalter).
Beispiel: Schauplatz "Café Cubas" → alle Szenen dort.
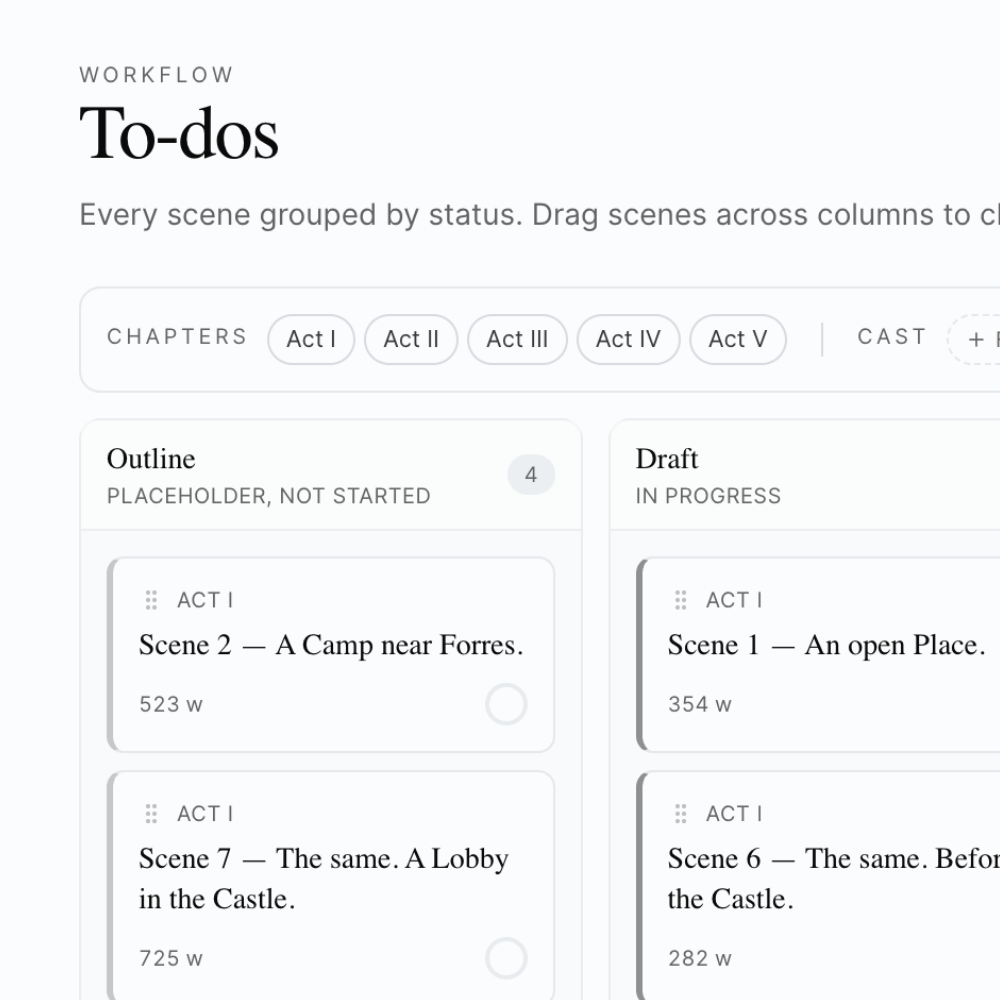
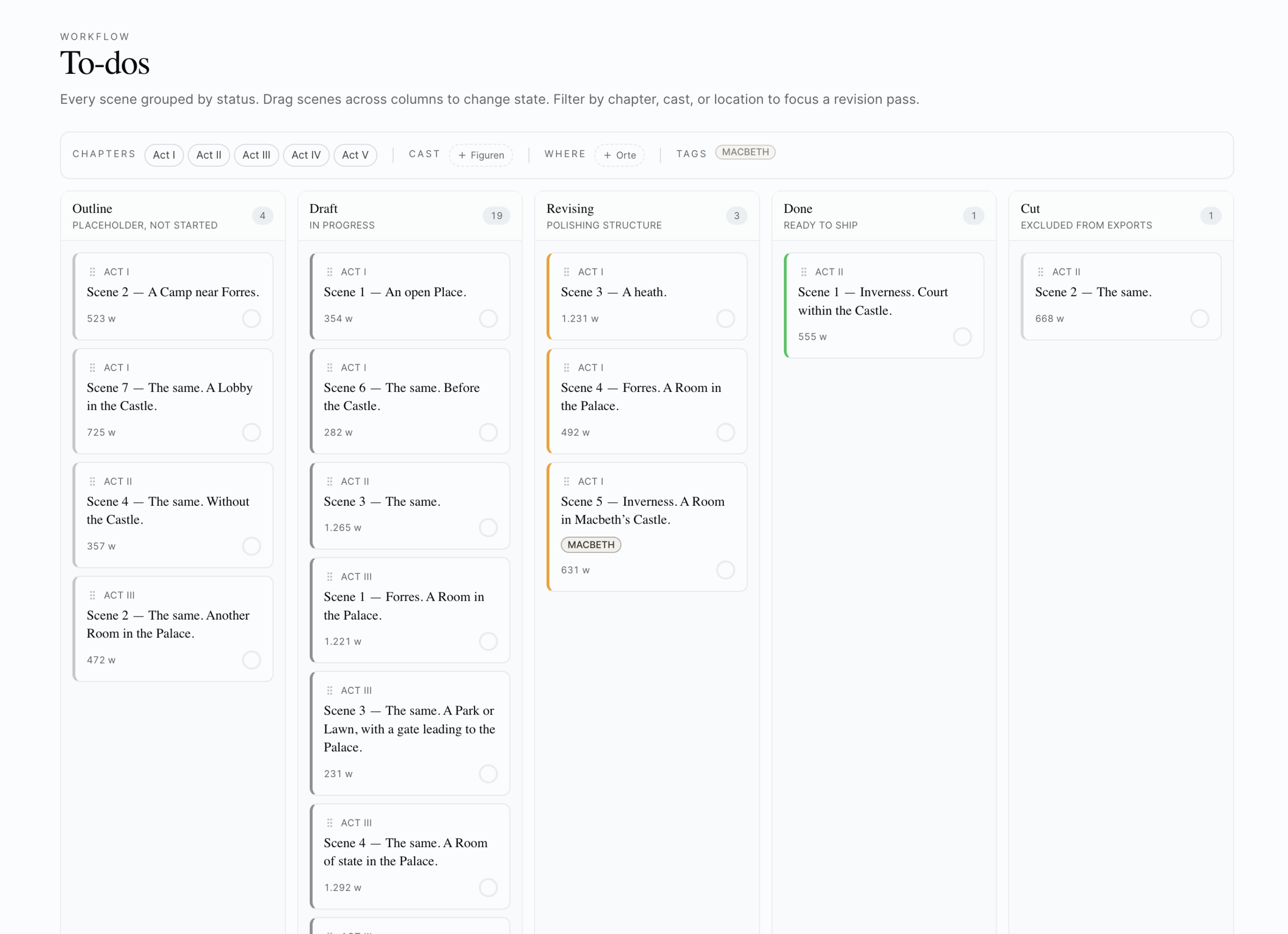
Status
Welche Stadien aus dem To-do-Board? Eine Liste von Stati — Outline, Draft, Revising, Done, Cut. Logik: ODER.
Beispiel: "nur Done und Revising" → nur die Szenen, an denen ich aktiv bin oder die ich für fertig halte. Outline-Skizzen werden ausgeblendet.
Tags
Welche frei vergebenen Etiketten? Wie Status-Logik (UND oder ODER per Schalter).
Beispiel: Tag "Konflikt" → nur Szenen, die ich als Konflikt markiert habe.
Volltext-Suche
Eine Phrase oder ein Wort, das in Szenentitel oder Kapiteltitel vorkommt. Fuzzy gematcht.
Beispiel: "Tatort" → alle Szenen mit "Tatort" im Titel.
Set-weiter Mode
Über alle aktiven Filter spannt sich ein letzter Schalter: AND (Standard, alle Bedingungen müssen erfüllt sein) oder OR (eine reicht).
Mit AND ist der Filter eine Konjunktion: "POV Anna AND Schauplatz Cubas AND Status Revising" → nur die Szenen, die alles erfüllen.
Mit OR ist er eine Disjunktion: "POV Anna OR Schauplatz Cubas OR Status Revising" → alle Szenen, die irgendetwas davon erfüllen — eine breite Sicht für Übersicht.
Wo Filter-Sätze überall greifen
Hier liegt der eigentliche Wert. Ein gespeicherter Filter funktioniert an drei Stellen:
1. Im Editor (Manuskript-Spalte)
In der seitlichen Spalte des Editors siehst du normalerweise alle deine Szenen. Mit aktivem Filter siehst du nur die passenden — gegliedert nach Kapiteln, mit den Szenen, die hineinfallen. Du klickst eine an, der Editor öffnet sie. Du arbeitest in einer fokussierten Subset-Sicht.
2. Im Lese-Modus (Compiled View)
Wenn du auf "Lesen" wechselst (siehe Export & Compile), wird das Buch typografisch gesetzt dargestellt — und auch hier respektiert es den aktiven Filter. Du liest nur deine Anna-POV-Szenen, am Stück, gesetzt wie ein gedrucktes Buch.
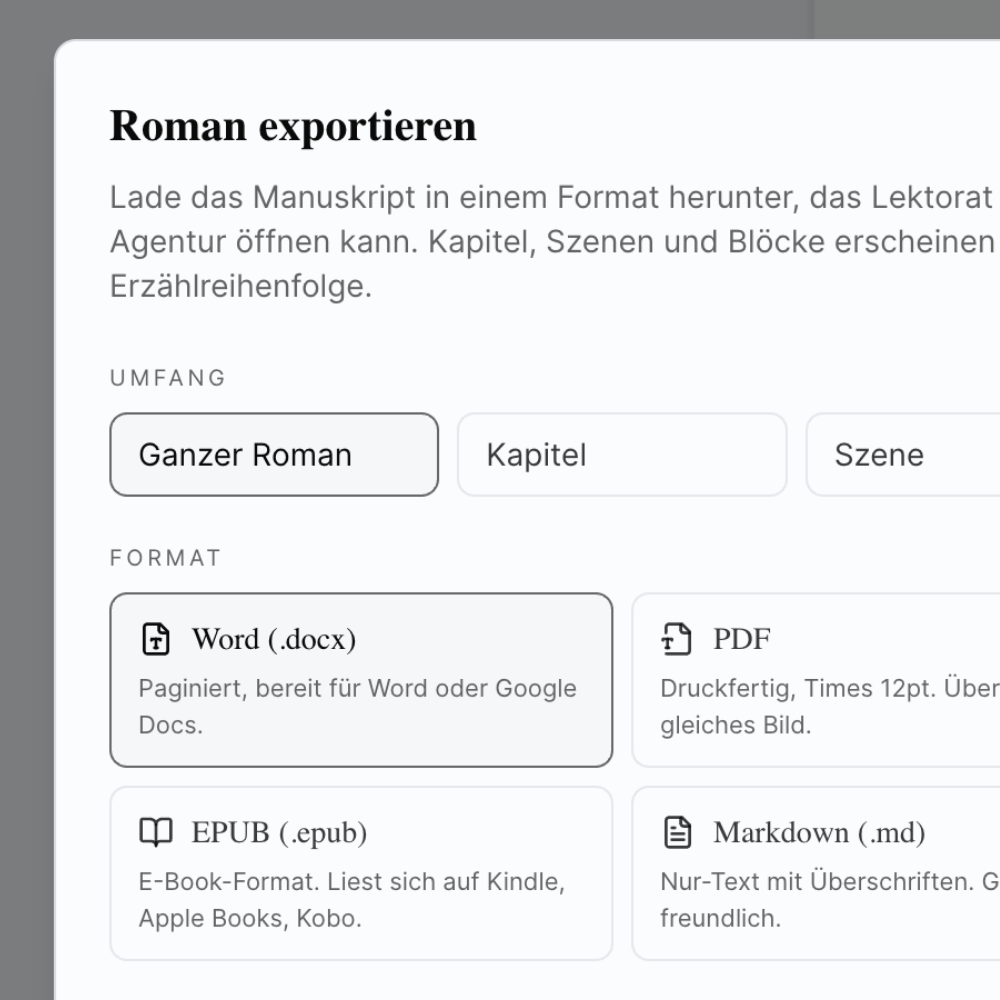
3. Im Export-Dialog
Klickst du auf Export bei aktivem Filter, übernimmt der Dialog die gefilterten Szenen automatisch. Eine Markierung "Filter aktiv" zeigt es dir. Du exportierst genau diesen Subset als DOCX, EPUB, PDF oder Markdown.
Drei Sichten — Editor, Lese-Modus, Export — geteilte Filter-Logik. Eine gespeicherte Suche, drei Anwendungen.
Konkrete Anwendungsfälle
"Lies Anna's Bogen am Stück"
Filter: POV = Anna, Status = "alles außer Cut". Aktivier ihn vor der Lese-Sitzung. Der Lese-Modus zeigt dir nur Annas Szenen, gesetzt wie ein Buch. Du liest fließend ihren Bogen, ohne dass Bob dazwischenfunkt.
"Schick Akt 1 an die Beta-Leserin, ohne ausgeschnittene Szenen"
Filter: Tag = "Akt 1", Status = "nicht Cut", optional auch "nicht Outline". Aktivier ihn, klick auf Export, wähle DOCX. Die Lektorin bekommt eine saubere Datei — Akt 1, ohne Notizen, ohne Skizzen, ohne ausgeschnittene Szenen.
"Welche Szenen sind noch in Outline?"
Filter: Status = Outline. Aktivier ihn im Editor. Du siehst auf einen Blick, was noch unfertig ist und in welchen Kapiteln die Lücken sind.
"Alle Szenen, in denen Anna UND Bob im Café Cubas sind"
Filter: Cast (alle) = Anna + Bob, Schauplatz = Café Cubas. Eine sehr spezifische Sicht — vielleicht für eine Konsistenz-Prüfung deiner zentralen Treffen.
"Szenen mit Tag 'Subhandlung-B'"
Wenn du deine Subhandlungen taggst, kannst du jederzeit isoliert auf eine Subhandlung schauen. Filter: Tag = "Subhandlung-B". Im Lese-Modus liest du den B-Bogen am Stück; siehst Lücken, schiefe Übergänge, fehlende Beats.
"Backup nur fertige Szenen als Markdown"
Filter: Status = Done. Export: Markdown. Ergebnis: dein "stabiles" Manuskript zum Sichern oder in ein anderes Tool zu importieren.
Filter speichern, bearbeiten, löschen
Du baust einen Filter im Filter-Dialog (an der Manuskript-Spalte, ein kleines Filter-Symbol). Du klickst "Filter speichern", gibst einen Namen — z.B. "Anna POV Akt 2". Der Filter erscheint in deiner Filter-Liste. Bei zukünftigen Sitzungen ein Klick: aktiv.
- Bearbeiten: Du wählst einen gespeicherten Filter, änderst Bedingungen, klickst "Aktualisieren". Das spart dir das Neu-Anlegen für ähnliche Sichten.
- Umbenennen: Im selben Dialog. Maximal 80 Zeichen.
- Löschen: Eine Müll-Symbol an jedem Filter, mit Bestätigungsdialog.
Filter sind pro Roman und pro Benutzer:in. Wenn du an drei Romanen arbeitest, hat jeder seine eigene Filter-Liste. Wenn ihr zu zweit am gleichen Roman schreibt, hat jede:r eigene Filter (es gibt derzeit keine geteilten Filter zwischen Co-Autor:innen).
Wo Word, Scrivener und Papyrus anders funktionieren
Word hat keine Filter. Du suchst, du findest, du arbeitest mit Lesezeichen. Das ist nicht annähernd das gleiche.
Scrivener hat Collections, die ähnlich sind. Aber Collections sind:
- Manuell kuratiert, nicht abfragebasiert. Du fügst Szenen manuell hinzu. Wenn du in Woche 7 eine neue Anna-Szene schreibst, ist sie nicht automatisch in der "Anna POV"-Collection.
- An eine Sicht gebunden, nicht an drei. Im Compile musst du die Sicht erneut konfigurieren.
Papyrus Autor hat keine Sicht-Filter. Du arbeitest am durchgehenden Manuskript.
Novumdrafts Filter sind anders, weil:
- Abfragebasiert, nicht manuell. Wenn du Cast = Anna setzt, sind alle Anna-Szenen drin — auch die, die du nächste Woche schreibst.
- Querverwendbar. Editor + Lese-Modus + Export. Drei Anwendungen, eine Konfiguration.
- Kombinierbar. POV UND Cast UND Schauplatz UND Status UND Tags UND Volltext.
Was Filter-Sätze (noch) nicht können
-
Lektor-Kontext-Filter: Wenn du das Lektorat etwas fragst, liest es das ganze Manuskript. Du kannst derzeit nicht sagen "lies nur die Anna-POV-Szenen".
-
Filter-Vorlagen: Es gibt keine eingebauten Default-Filter (à la "alle Cut-Szenen" oder "alle Revising-Szenen"). Du legst alle Filter selbst an.
-
Geteilte Filter zwischen Co-Autor:innen: Filter sind pro Benutzer:in. Wenn ihr zu zweit am Roman schreibt, hat jede:r eigene Filter. Eine Team-Filter-Funktion ist denkbar, aber nicht eingebaut.
-
Filter-Verkettung: "Set A, aber nicht Set B" — also Komplement-Filter — ist nicht möglich.
-
Filter-getriebene Statistiken: Es gibt keine "Wortzahl in Filter X"-Auswertung getrennt vom Editor.
Wie du anfängst
- Schreib ein paar Szenen — mindestens zehn, in unterschiedlichen Status-Stadien, mit verschiedenen Figuren.
- Geh in den Manuskript-Editor. In der Spalte mit den Szenen findest du oben einen Filter-Knopf.
- Setz einen einfachen Filter — etwa "Status = Draft". Klick auf "Speichern", gib ihm den Namen "Aktive Entwürfe".
- Wechsle in den Lese-Modus. Du siehst dieselben gefilterten Szenen — nur, dass sie jetzt typografisch gesetzt erscheinen.
- Wechsle in den Export. Du siehst die "Filter aktiv"-Markierung. Wähle ein Format, klick Export.
Nach drei, vier solchen Filter-Sätzen wirst du anders über deinen Roman denken: nicht mehr als ein langes Dokument, sondern als ein System mit verschiedenen Ansichten — die du je nach Aufgabe wählst.
Datenschutz
Filter-Definitionen sind Teil deines Roman-Projekts und werden auf Novumdraft-Servern verschlüsselt gespeichert. Sie verlassen dein Konto nicht und werden nicht zum Trainieren von KI-Modellen verwendet.
Mehr Details findest du in der Datenschutzerklärung.
In welchen Plänen Filter-Sätze enthalten sind
Filter-Sätze sind Teil aller Novumdraft-Pläne — Autor und Profi. Es gibt kein Limit auf die Anzahl gespeicherter Filter pro Roman.
Bereit, dein Manuskript anders zu sehen?
Starte ein 14-tägiges, kostenloses Testen. Schreib ein paar Szenen. Bau deinen ersten Filter — etwa "POV: Hauptfigur" — und sieh dein Buch nur durch die Brille dieser Figur.
Du wirst Strukturen entdecken, die im durchgehenden Manuskript nicht sichtbar waren.
14 Tage kostenlos testen
Ohne Kreditkarte. Kündbar jederzeit.
Weitere Funktionen